Storm models are crucial to law reform. One needs them to get a sense if premiums are reasonable. And, as I want to show in a series of blog posts, they can also help figure out the effect of legally mandated changes to the insurance contract. You need to tie behavior at the level of the individual policyholder to the long term finances of the insurer. How would, for example, changing the required deductible on windstorm policies issued by the Texas Windstorm Insurance Association affect the precautions taken by policyholders to avoid storm damage? That’s important for many reasons, among them that it affects the sustainability of TWIA. Might the imposition of coinsurance into the insurance contract do a better job of making TWIA sustainable? These are the kind of questions for which a decent storm model is useful.
So, over the past few weeks I’ve been thinking again about ways in which one could, without access (yet) to gigabytes of needed data, develop approximations of the windstorm damage events likely to be suffered by policyholders. And I’ve been thinking about ways in which one could parameterize those individual damages as a function of the level of precautions taken by policyholders to avoid damage.
What I’m going to present here is a model of storm damage that attempts to strike a reasonable balance of simplicity and fidelity. I’m afraid there’s a good bit of math involved, but I’m going to do my best here to clarify the underlying ideas and prevent your eyes from glazing over. So, if you’ll stick with me, I’ll do my best to explain. The reward is that, at the end of the day, we’re going to have a model that in some ways is better than what the professionals use. It not only explains what is currently going on but can make predictions about the effect of legal change.
Let’s begin with two concepts: (1) “claim prevalence” and (2) “mean scaled claim size.” By “claim prevalence,” which I’m going to signify with the Greek letter [latex]\nu[/latex] (nu), I mean the likelihood that, in any given year, a policyholder will file a claim based on an insured event. Thus, if in a given year 10,000 of TWIA’s 250,000 policyholders file a storm damage claim, that year’s prevalence is 0.04. “Mean scaled claim size,” which I’m going to signify with the Greek letter [latex]\zeta[/latex] (zeta), is a little more complicated. It refers to the mean of the size of claims filed during a year divided by the value of the property insured for all properties on which claims are filed during a year. To take a simple example, if TWIA were to insure 10 houses and, in a particular year, and 2 of them filed claims ([latex]\nu =0.2[/latex]) for $50,000 and for $280,000, and the insured values of the property were $150,000 and $600,000 respectively, the mean scaled claim size [latex]\zeta[/latex] would be 0.4. That’s because: [latex]0.4=\frac{50}{2\ 150000}+\frac{280000}{2\ 600000}[/latex].
Notice, by the way, that [latex]\zeta \times \nu[/latex] is equal to aggregate claims in a year as a fraction of total insured value. Thus, if [latex]\zeta \times \nu = 0.005[/latex] and the total insured value is, say, $71 billion, one would expect $355 million in claims in a year. I’ll abbreviate this ratio of aggregate claims in a year to total insured value as [latex]\psi[/latex] (psi). In this example, then, [latex]\psi=0.005[/latex].[1]
The central idea underlying my model is that claim prevalence and mean scaled claim size are positively correlated. That’s because both are likely to correlate positively with the destructive power of the storms that occurred during that year. The correlation won’t be perfect. A tornado, for example, may cause very high mean scaled claim sizes (total destruction of the homes it hits) but have a narrow path and hit just a few insured properties. And a low grade tropical storm may cause modest levels of wind damage among a large number of insureds. Still, most of the time, I suspect, bigger stoms not only cause more claims, but they increase the size of the scaled mean claim size.
A copula distribution provides a relatively simple way of blending correlated random variables together. There are lots of explanations: Wikipedia, a nice paper on the Social Science Research Network, and the Mathematica documentation on the function that creates copula distributions. There are lots of ways of doing this blending, each with a different name. I’m going to stick with a simple copula, however, the so-called “Binormal Copula” (a/k/a the “Gaussian Copula.”) with a correlation coefficient of 0.5.[2]
To simulate the underlying distributions, I’m going to use a two-parameter beta distribution for both claim prevalence mean scaled claim size. My experimentation suggests that, although there are probably many alternatives, both these distributions perform well in predicting the limited data available to me on these variables. They also benefit from modest analytic tractability. For people trying to recreate the math here, the distribution function of the beta distribution is [latex]I_x\left(\left(\frac{1}{\kappa ^2}-1\right) \mu ,\frac{\left(\kappa ^2-1\right) (\mu -1)}{\kappa ^2}\right)[/latex], where [latex]\mu[/latex] is the mean of the distribution and [latex]\kappa[/latex] is the fraction (0,1) of the maximum standard deviation of the distribution possible given the value of [latex]\mu[/latex]. What I have found works well is to set [latex]\mu _{\nu }=0.0244[/latex], [latex]\kappa _{\nu }=0.274[/latex] for the claim prevalence distribution and [latex]\mu _{\zeta }=0.097[/latex], [latex]\kappa _{\zeta }=0.229[/latex] for the mean scaled claim size distribution. This means that policyholders will file a claim about every 41 years and that the value of claims for the year will, on average, be 9.7% of the insured value of the property.[3]
We can visualize this distribution in a couple of ways. The first is to show a probability density function of the distribution but to scale the probability logarithmically. This is shown below.

PDF of sample copula distribution
The second is to simulate 10,000 years worth of experience and to place a dot for each year showing claim prevalence and mean scaled claim size. That is done below. I’ve annotated the graphic with labels showing what might represent a year in which there was a tornado outbreak, a catastrophic hurricane, a tropical storm as well as the large cluster of points representing years in which there was minimal storm damage.

Claim prevalence and mean scaled claim size for 10,000 year simulation
Equipped with our copula, we can now generate losses at the individual policyholder level for any given year. The idea is to create a “parameter mixture distribution” using the copula. As it turns out, one component of this parameter mixture distribution is itself a mixture distribution.
Dear reader, you now have a choice. If you like details, have a little bit of a mathematical background and want to understand better how this model works, just keep reading at “A Mini-Course on Mixture and Parameter Mixture Distributions.” If you just want the big picture, skip to “Simulating at the Policyholder Level” below.
A Mini-Course on Mixture and Parameter Mixture Distributions
To fully understand this model, we need some understanding of a mixture distribution and a parameter mixture distribution. Let’s start with the mixture distribution, since that is easier. Imagine a distribution in which you first randomly determine which underlying component distribution you are going to use and then you take a draw from the selected underlying component distribution. You might, for example, roll a conventional six-sided die, which is a physical representation of what statisticians call a “discrete uniform distribution.” If the die came up 5 or 6, you then draw from a beta distribution with a mean of 0.7 and a standard deviation of 0.3 times the maximum. But if the die came up 1 through 4, you would draw from a uniform distribution on the interval [0,0.1]. The diagram below shows the probability density function of the resulting mixture distribution (in red) and the underlying components in blue.

Mixture Distribution with beta and uniform components
The mixture distribution has a finite number of underlying component distributions and has discrete weights that you select. The parameter mixture distribution can handle both infinite underlying component distributions and handles weights that are themselves draws from a statistical distribution. Suppose we create a continuous function [latex]f[/latex] that takes a parameter [latex]x[/latex] and creates triangular distribution which has a mean of [latex]x[/latex] and extends 1/4 in each direction from the mean. We will call this triangular distribution the underlying distribution of the parameter mixture distribution. The particular member of the triangular distribution family used is determined by the value of the parameter. And, now, we want to create a “meta distribution” — a parameter mixture distribution — in which the probability of drawing a particular parameter [latex]x[/latex] and in turn getting that kind of triangular distribution with mean [latex]x[/latex] is itself determined by another distribution, which I will call [latex]w[/latex]. The distribution [latex]w[/latex] is the weighting distribution of the parameter mixture distribution. To make this concrete, suppose [latex]w[/latex] is a uniform distribution on the interval [0,1].
The diagram below shows the result. The blue triangular underlying distributions represent a sample of the probability density functions of triangular distributions. There are actually an infinite number of these triangular distributions, but obviously I can’t draw them all here. Notice that some of the density functions are more opaque than others. The opacity of each probability density function is based on the probability that such a distribution would be drawn from [latex]w[/latex]. The red line shows the probability density function of the resulting parameter mixture distribution. It is kind of an envelope of these triangular distributions.

Parameter mixture distribution for triangular distributions where mean of triangular distributions is drawn from a uniform distribution
We can combine mixture distributions and parameter mixture distributions. We can have a mixture distribution in which one or more of the underlying functions is a parameter mixture distribution. And, we can have a parameter mixture distribution in which either the underlying function and/or the weighting function is a mixture distribution.
It’s that combination — a parameter mixture distribution in which the underlying function is a mixture distribution — that we’re going to need to get a good simulation of the damages caused by storms. The weighting distribution of this parameter mixture distribution is our copula. It throws out two parameters: (1) [latex]\nu[/latex], the likelihood that in any given year the policyholder has a non-zero claim and (2) [latex]\zeta[/latex] the mean scaled claim size assuming that the policyholder has a non-zero claim. Those two parameters are going to weight members of the underlying distribution, which is a mixture distribution. The weights of the mixture distribution are the the likelihood that the policyholder has no claim and the likelihood that the policyholder has a non-zero claim (claim prevalence). The component distributions of the mixture distribution are (1) a distribution that always produces zero and (2) any distribution satisfying the constraint that its mean is equal to the mean scaled claim size. I’m going to use another beta distribution for this latter purpose with a standard deviation equal to 0.2 of the maximum standard deviation. I’ll denote this distribution as B. Some examination of data from Hurricane Ike is not inconsistent with the use of this distribution and the distribution has the virtue of being analytically tractable and relatively easy to compute.
This diagram may help understand what is going on.

The idea behind the parameter mixture distribution
Simulating at the Policyholder Level
So, we can now simulate a large insurance pool over the course of years by making, say, 10,000 draws from our copula. And from each draw of the copula, we can determine the claim size for each of the policyholders insured in that sample year. Here’s an example. Suppose our copula produces a year with some serious damage: claim prevalence value of 0.03 and a mean scaled claim size of 0.1 for the year. If we simulate the fate of 250,000 policyholders, we find that 242,500 have no claim. The graphic below shows the distribution of scaled claim sizes among those who did have a non-zero claim.

Scaled claim sizes for sample year
Fortunately, however, we don’t need to sample 250,000 policy holders each year for 10,000 years to get a good picture of what is going on. We can simulate things quite nicely by looking at the condition of just 2,500 policyholders and then just multiplying aggregate losses by 100. The graphic below shows a logarithmic plot of aggregate losses assuming a total insured value in the pool of $71 billion (which is about what TWIA has had recently).

Aggregate losses (simulated) on $71 billion of insured property
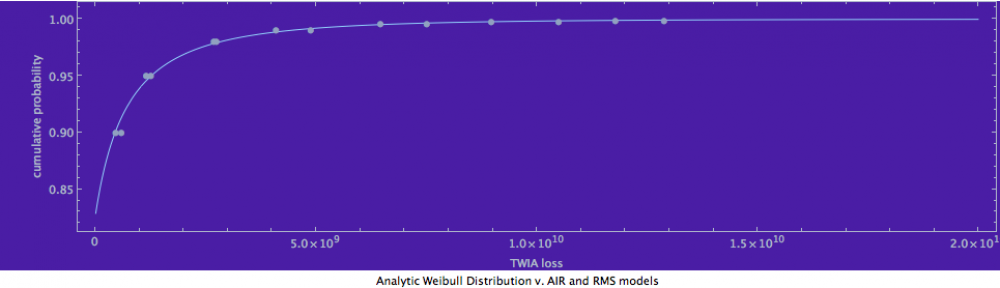
We can also show a classical “exceedance curve” for our model. The graphic below varies the aggregate losses on $71 billion of insured property and shows, for each value, the probability (on a logarithmic scale) that losses would exceed that amount. One can thus get a sense of the damage caused by the 100 year storm and the 1000-year storm. The figures don’t perfectly match TWIA’s internal models, but that’s simply because our parameters have not been tweaked at this point to accomplish that goal.

Exceedance curve (logarithmic) for sample 10,000 year run
The final step is to model how extra precautions by a policyholder might alter these losses. Presumably, precautions are like most economic things: there is a diminishing marginal return on investment. So, I can roughly model matters by saying that for a precaution of x the insured results in the insured drawing from a new beta distribution with a mean equal to [latex]\ell \times 2^{-x}[/latex], where [latex]\ell[/latex] is the amount of damage they would have suffered had they taken no extra precautions. (I’ll keep the standard deviation of this beta distribution equal to 0.2 of its maximum possible value.) I have thus calibrated extra precautions such that each unit of extra precautions cuts the mean losses in half. It doesn’t mean that sometimes precautions won’t result in greater savings or that sometimes precautions won’t result in lesser savings; it just means that on average, each unit of precautions cuts the losses in half.
And, we’re done! We’ve now got a storm model that when combined with the model of policyholder behavior that I will present in a future blog entry, should give us respectable predictions on the ability of insurance contract features such as deductibles and coinsurance to alter aggregate storm losses. Stay tuned!
Footnotes
[1] As I recognized a bit belatedly in this project, if one makes multiple draws from a copula distribution, it is not the case that the mean of the product of the two values [latex]\nu[/latex] and [latex]\zeta[/latex] drawn from the copula is equal to [latex]\nu \times \zeta[/latex]. You can see why this might be by imagining a copula distribution in which the two values were perfectly correlated, in which case one would be drawing from a distribution transformed by squaring. It is not the case that the mean of such a transformed distribution is equal to the mean of the underlying distribution.
[2] Copulas got a bad name over the past 10 years for bearing some responsibility for the financial crisis.. This infamy, however, has nothing to do with the mathematics of copulas, which remains quite brilliant, but with their abuse and the fact that incorrect distributions were inserted into the copula.
[3] We thus end up with a copula distribution whose probability density function takes on this rather ghastly closed form. (It won’t be on the exam.)
[latex]\frac{(1-\zeta )^{\frac{1-\mu _{\zeta }}{\kappa _{\zeta }^2}+\mu _{\zeta }-2} \zeta ^{\left(\frac{1}{\kappa _{\zeta }^2}-1\right) \mu _{\zeta }-1} (1-\nu )^{\frac{1-\mu _{\nu }}{\kappa _{\nu }^2}+\mu _{\nu }-2} \nu ^{\left(\frac{1}{\kappa _{\nu }^2}-1\right) \mu_{\nu }-1} \exp \left(\frac{\left(\text{erfc}^{-1}\left(2 I_{\zeta }\left(\left(\frac{1}{\kappa _{\zeta }^2}-1\right) \mu _{\zeta },\frac{\left(\kappa _{\zeta }^2-1\right) \left(\mu _{\zeta }-1\right)}{\kappa _{\zeta }^2}\right)\right)-\rho
\text{erfc}^{-1}\left(2 I_{\nu }\left(\left(\frac{1}{\kappa _{\nu }^2}-1\right) \mu _{\nu },\frac{\left(\kappa _{\nu }^2-1\right) \left(\mu _{\nu }-1\right)}{\kappa _{\nu }^2}\right)\right)\right){}^2}{\rho ^2-1}+\text{erfc}^{-1}\left(2 I_{\zeta
}\left(\left(\frac{1}{\kappa _{\zeta }^2}-1\right) \mu _{\zeta },\frac{\left(\kappa _{\zeta }^2-1\right) \left(\mu _{\zeta }-1\right)}{\kappa _{\zeta }^2}\right)\right){}^2\right)}{\sqrt{1-\rho ^2} B\left(\left(\frac{1}{\kappa _{\zeta }^2}-1\right) \mu _{\zeta
},\frac{\left(\kappa _{\zeta }^2-1\right) \left(\mu _{\zeta }-1\right)}{\kappa _{\zeta }^2}\right) B\left(\left(\frac{1}{\kappa _{\nu }^2}-1\right) \mu _{\nu },\frac{\left(\kappa _{\nu }^2-1\right) \left(\mu _{\nu }-1\right)}{\kappa _{\nu }^2}\right)}[/latex]








